



IBM’s Latest Prototype Low-Power AI Chip Offers ‘Precision Scaling’

Source: IBM Research
IBM has released details of a prototype AI chip geared toward low-precision training and inference across different AI model types while retaining model quality within AI applications.
In a paper delivered during this year’s International Solid-State Circuits Virtual Conference, IBM also touted its AI chip based on 7nm process technology as the first energy-efficient device “at the vanguard of low precision training and inference.”
The low-power AI hardware accelerator is being targeted at applications ranging from cloud-based model training to shifting training closer to the edge deployments and data closer to edge network sources. Those scenarios would boost processing power in hybrid cloud environments without exacting a power penalty, the company said.
The “rapid evolution of AI model complexity also increases the technology’s energy consumption,” IBM researchers Ankur Agrawal and Kailash Gopalakrishnan noted in a blog post unveiling the AI chip design.
“We want to change this approach and develop an entire new class of energy-efficient AI hardware accelerators that will significantly increase compute power without requiring exorbitant energy,” they wrote. The would result, they added, in precision scaling.
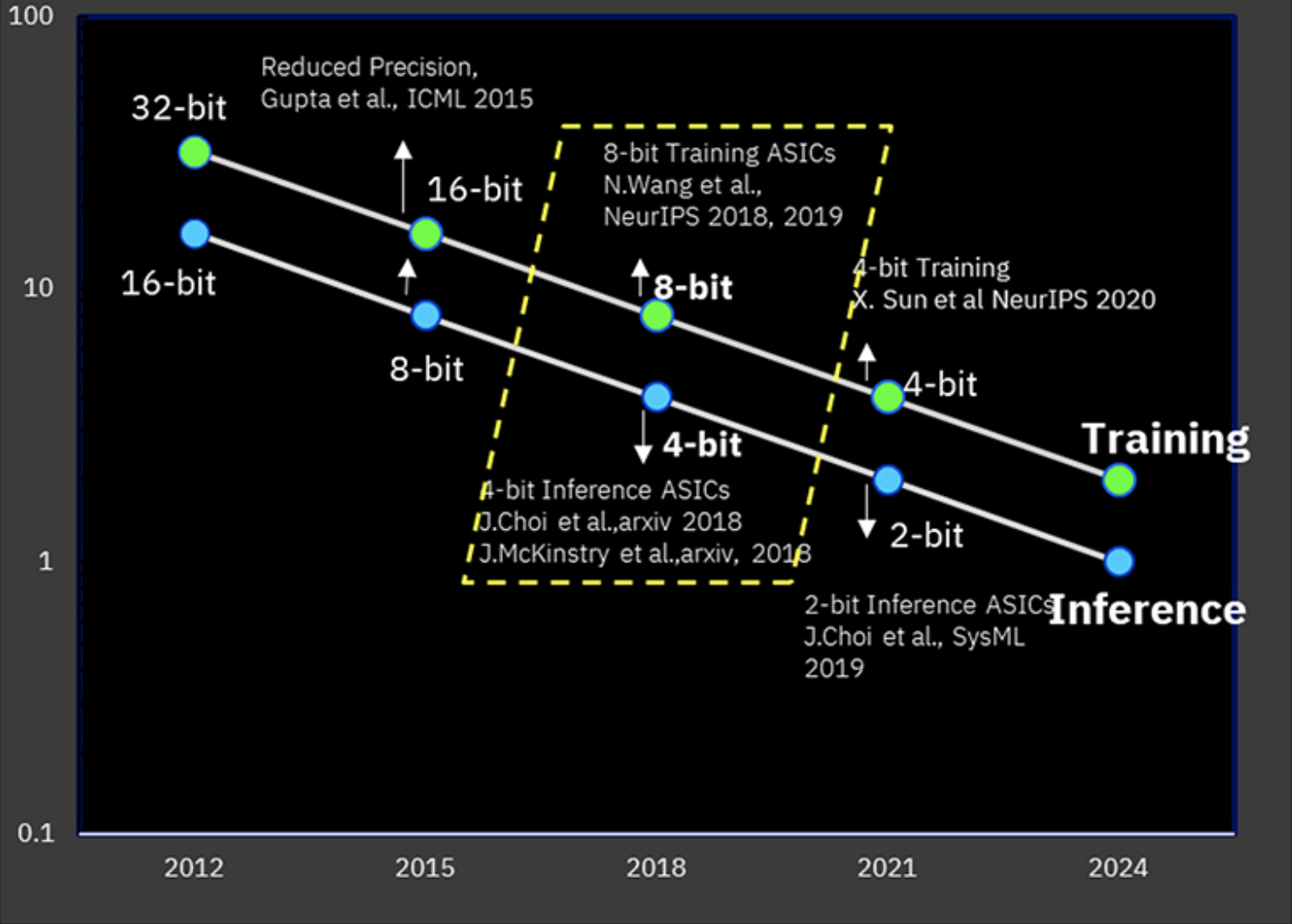
IBM has been steadily improving the power performance ratio of its AI chips over the last half-decade. Along with algorithms that boost training and inference without sacrificing prediction accuracy, new chip designs on advanced fabrication nodes have been leveraged to handle complex workloads with greater power efficiency.
One approach reduced precision formats to 8 bits for training and 4 bits for inference, adding communications protocols that allow AI cores on a multi-core chip to exchange data. Designers recently demonstrated 4-bit training format at NeurIPS 2020. The goal is cutting training time and cost while erasing the “blurry border between cloud and edge computing,” the researchers noted.
IBM's AI chip is optimized to perform 8-bit training and 4-bit inference on a range of AI models without model accuracy degradation. (Source: IBM Research)
The new AI silicon incorporates hybrid 8-bit floating point training and inference used for training deep learning models. The device is based on a 7nm chip fabricated using extreme UV process technology. The combination outperforms other dedicated inference and training chips in terms of performance and power consumption, IBM claims.
“We show that we can maximize the performance of the chip within its total power budget, by slowing it down during computation phases with high power consumption,” the researchers added. One reason is “high sustained utilization that translates to real application performance and is a key part of engineering our chip for energy efficiency.”
The payoff would be AI models that scale performance while reducing power consumption. The designers foresee edge applications for their low-power AI accelerator spanning deep learning models for machine vision, speech and natural language processing (NLP). Those models could replace current 16- and 32-bit formats used in many enterprise applications with lower-power 8-bit formats.
IBM also touts its approach as suited to cloud inference applications ranging from speech-to-text and text-to-speech along with NLP services and fraud detection.
Analysts note the latest IBM AI accelerator is a prototype, but that it does address key requirements for deploying AI models. “Energy efficiency with lower precision math does more than save on power, it can dramatically increase performance,” said Karl Freund, principal analyst at Cambrian-AI Research.
“It will be up to a design team to decide how to leverage this technology when it becomes available. This is still a test chip, but the promise IBM Research is offering is quite compelling,” Freund added.







